Organisation og referencegruppestruktur
DeiC koordinerer den nationale digitale forskningsinfrastruktur som et samarbejde med og mellem de danske universiteter.
DeiCs juridiske grundlag er beskrevet i bekendtgørelse BEK 615 af 26/05/2023.
DTU er værtsuniversitet for DeiC, og medarbejderne er ansat på DTU.
DeiC ledes af en bestyrelse, som på vegne af universiteterne har ansvaret for den overordnede og strategiske ledelse samt drift af samarbejdet.
Bestyrelsen ansætter en direktør for DeiC, som varetager den daglige ledelse. Direktøren er ansat på værtsuniversitetet.
Den daglige ledelse har ansvaret for DeiC’s driftsaktiviteter, udviklingsaktiviteter, samarbejdsprojekter og øvrige initiativer, der besluttes af bestyrelsen.
DeiCs bestyrelse
Bestyrelsen er udpeget af Uddannelses- og Forskningsstyrelsen efter indstilling fra Danske Universiteter, og består af en person fra ledelsesniveauet på hvert universitet.
Organisationsdiagram
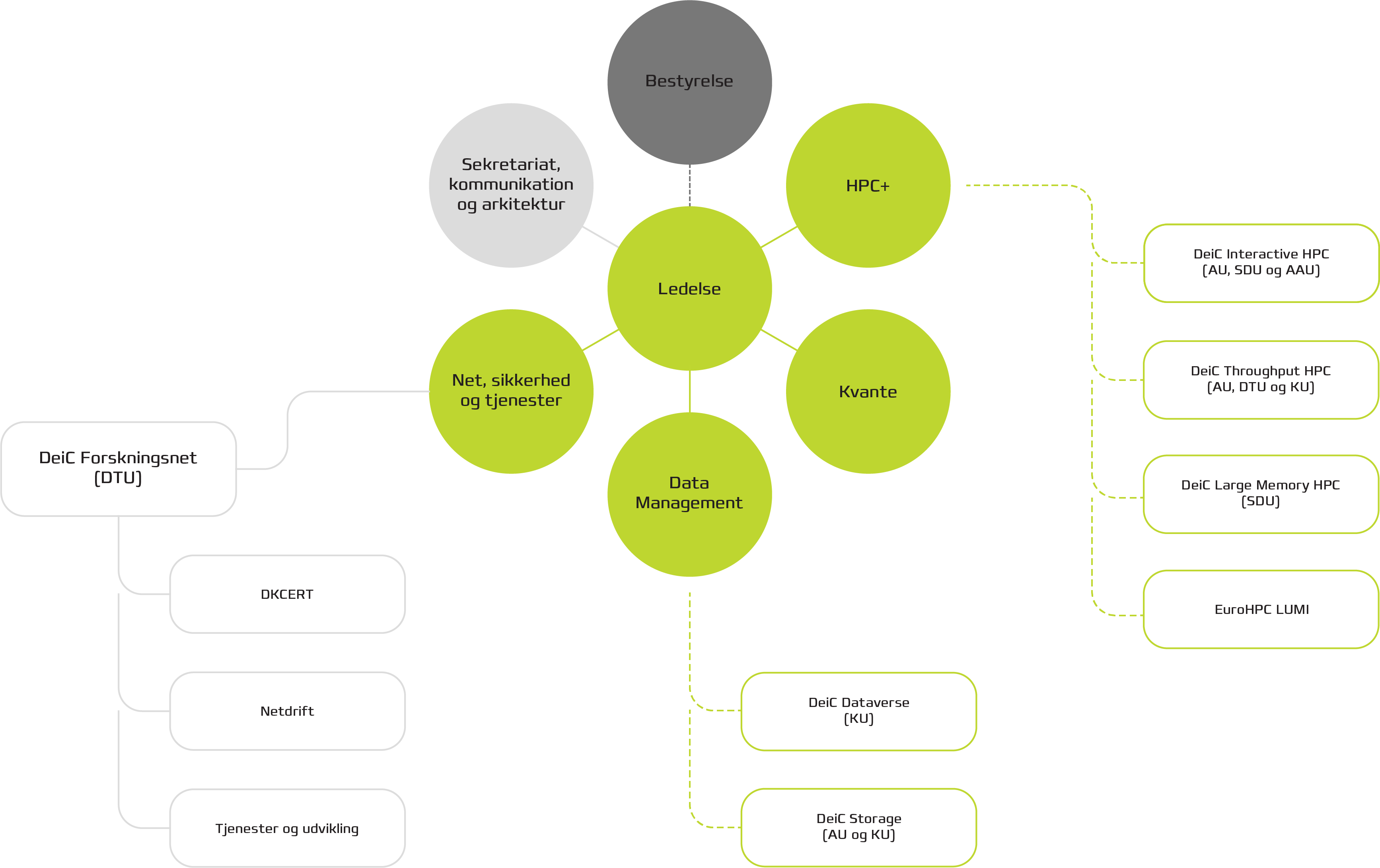
Ledelsesstruktur
Den daglige leder af DeiC og ansvarlige overfor bestyrelsen er konstitueret direktør Martin Bech. Ledelsesteamet består udover direktøren af Chef for HPC+ Rune Gamborg Ørum, Chef for Datamanagement Anne Sofie Fink Kjeldgaard og Chef for Kvanteområdet Henrik Navntoft Sønderskov.
DeiC koordinerer leverancen af den digitale forskningsinfrastruktur, som leveres af universiteterne.
DeiC Forskningsnettet driftes af DTU. DeiC Forskningsnettet betragtes som et ”datterselskab” til DeiC, og DeiCs bestyrelse er ansvarlig for økonomi og tjenesteportefølje. Chef for Forskningsnettet Martin Bech referer til DeiCs direktør for de omfattede aktiviteter.
Leverancen af de øvrige infrastruktur-tjenester fra universiteterne reguleres via indgåede aftaler.
Referencegrupper
For at sikre en god dialog med universiteterne og inddrage brugerne af den digitale forskningsinfrastruktur i den nationale udvikling, har DeiCs bestyrelse nedsat en række referencegrupper. Medlemmerne af referencegrupperne er indstillet af deres universiteter, og repræsenterer universitetet i referencegruppen. Undtagelsen herfra er medlemmerne af Science Forum, der er indstillet i deres personlige egenskab.
Referencegrupperne er delt ind efter deres tidsmæssige sigte med aktiviteterne.
Drift
Driften af DeiC Forskningsnettet og tjenester herunder varetages af Chefen for Forskningsnettet med reference til DeiCs direktør.
Driften af den øvrige infrastruktur varetages af universiteter, der har budt ind på opgaven. Den daglige drift vil blive koordineret på tværs i de såkaldte "Back Office"-enheder, der består af de driftsansvarlige fra universiteterne og chefen for hhv. HPC+ og Data Management i DeiC.
Chefen fra DeiC er formand det relevante back office samarbejde.
Udover Back Office-enhederne er der nedsat et fordelingsudvalg (e-ressource-udvalg), der skal modtage og behandle ansøgninger om adgang til de nationale ressourcer på HPC- og data management-området.
Det Koordinerende Organ for Registerforskning (KOR) er et rådgivende organ under DeiC med reference til DeiCs bestyrelse. KOR har til formål at stimulere og styrke dansk registerforskning og medvirke til at skabe en større sammenhæng og koordination omkring danske og internationalt relaterede forskningsaktiviteter vedrørende registre og databaser.
1-3 års sigte
Referencegrupperne for det 1-3-årige sigte har til formål at følge aktiviteterne nationalt og internationalt på DeiCs hovedområder (HPC, data management og forskningsnet og tjenester) og rådgive bestyrelsen om services, aktiviteter og tiltag på området.
Net Forum har til formål at rådgive om udviklingen indenfor forskningsnet, funktionel sikkerhed og tjenester. Gruppen består af infrastrukturansvarlige fra universiteterne. De nuværende medlemmer af gruppen er udpeget for perioden 1. juli 2021 – 30. juni 2023.
HPC Forum har til formål at rådgive DeiCs bestyrelse om udviklingen af den nationale HPC-infrastruktur, deltagelse i internationale samarbejder og projekter og øvrige tiltag til fremme af HPC-anvendelsen i Danmark. De nuværende medlemmer af gruppen er udpeget for perioden 1. januar 2023 – 31. december 2025.
DM Rådgivende Forum har til formål at rådgive DeiCs bestyrelse om udviklingen af den nationale data management-infrastruktur, deltagelse i internationale samarbejder og projekter og øvrige tiltag til fremme af området. De nuværende medlemmer af gruppen er udpeget for perioden 1. januar 2023 – 31. december 2025.
Visioner
Formålet med Science Forum er at sikre en udvikling af infrastrukturen, der imødekommer fremtidens behov. Medlemmerne af gruppen er forskere, der anvender infrastrukturen, og er på forkant med anvendelsen.
Communities
Formålet med communities er at give rum for erfaringsudveksling på tværs af universiteterne inden for et bestemt område i en mere uformel struktur.
HPC TekRef (teknisk referencegruppe for HPC) er et forum for erfaringsudveksling mellem de lokale såvel som de nationale HPC-centre. Medlemmerne er typisk systemadministratorer. Formand for gruppen vælges af deltagerne.
Net TekRef (teknisk referencegruppe for netværk) er et forum for erfaringsudveksling mellem net- og servicedriftsenhederne på universiteterne og forskningsnet-drift og services. Medlemmerne er typisk netværksadministratorer fra universiteterne. Formand for gruppen vælges af deltagerne.