
Niels Brügger forsker og skriver om de digitale mediers historie. I den forbindelse er han dykket ned i den danske del af World Wide Web og har analyseret den historiske webudvikling i perioden mellem 2005 og 2015.
”Det er et ret vildt projekt, og når jeg fortæller folk om det, så er reaktionen ofte: ”Aaarrhh, kan det nu lade sig gøre?” fortæller Niels Brügger, der er nyudnævnt professor i Medievidenskab på Aarhus Universitet.
”Men det kan det altså godt.”
Datagrundlaget for hans forskning, der er foretaget sammen med adjunkt Janne Nielsen fra Medievidenskab på Aarhus Universitet og Ditte Laursen fra Det Kgl. Bibliotek, er Netarkivet på Det Kgl. Bibliotek, hvor der opbevares en kopi af det danske net, svarende til omkring en million websites.
Oven på de mange data er der så lagt forskellige algoritmer, som har dannet rammeværket for udregningerne på DeiC’s High Performance Computer-anlæg, Kulturarvsclusteret, der er placeret på Det Kgl. Bibliotek i Aarhus.
Formålet med denne supercomputer er netop at give forskere, primært inden for de humanistiske og samfundsvidenskabelige områder, mulighed for at arbejde kvantitativt med big data.

”Samarbejdet mellem it-folk, arkivfolk og forskere har været en nødvendighed for at nå frem til konkrete resultater.” Niels Brügger, professor i Medievidenskab på Aarhus Universitet.
De fleste websites er 10 til 20 megabyte
Projektet har fra begyndelsen været opdelt i to hovedfaser.
Udgangspunktet er at skabe historisk viden om web i perioden fra 2005 til 2015.
Den anden del har handlet om at udvikle metoder og procedurer for, hvordan man skal gøre det i praksis via supercomputing.
”Den danske del af web har naturligvis udviklet sig i perioden, men ikke så voldsomt, som man måske skulle tro. I 2005 var det på fire TB og i 2015 var det kun cirka fire gange så stort,” fortæller han.
Men størrelsen har alligevel betydet, at der skulle solid computerkraft til at komme rundt i krogene.
Måden man valgte at angribe de mange data på var, populært sagt, ved at stikke en sonde ind i data-høstakken og suge de ønskede informationer ud.
”I første omgang handlede det om optælling af filer og objekter for at finde ud af, hvor store de danske websites egentlig er. Og faktisk er 97 procent af alle danske websites kun på mellem 10 og 20 megabyte.” fortæller han og fortsætter:
”Den resterende del er de helt store sites, hvis andel ikke har ændret sig væsentligt over de 10 år, vi har set på.”
Niels Brügger og hans team har ligeledes set på eksempelvis filtyper, andel af billeder, andel af password-beskyttede på det danske web for at kortlægge elementerne fra forskellige vinkler.
En af de kommende opgaver er at se på links fra samtlige sider. En opgave, der kræver en solid omgang datarensning for kun at få det samme link med én gang.
Samarbejde mellem humanister og it-folk
En af hovedopgaverne i forbindelse med projektet har været at finde sorteringsmetoder, algoritmer, som indsamler de definerede data i den store stak af informationer.
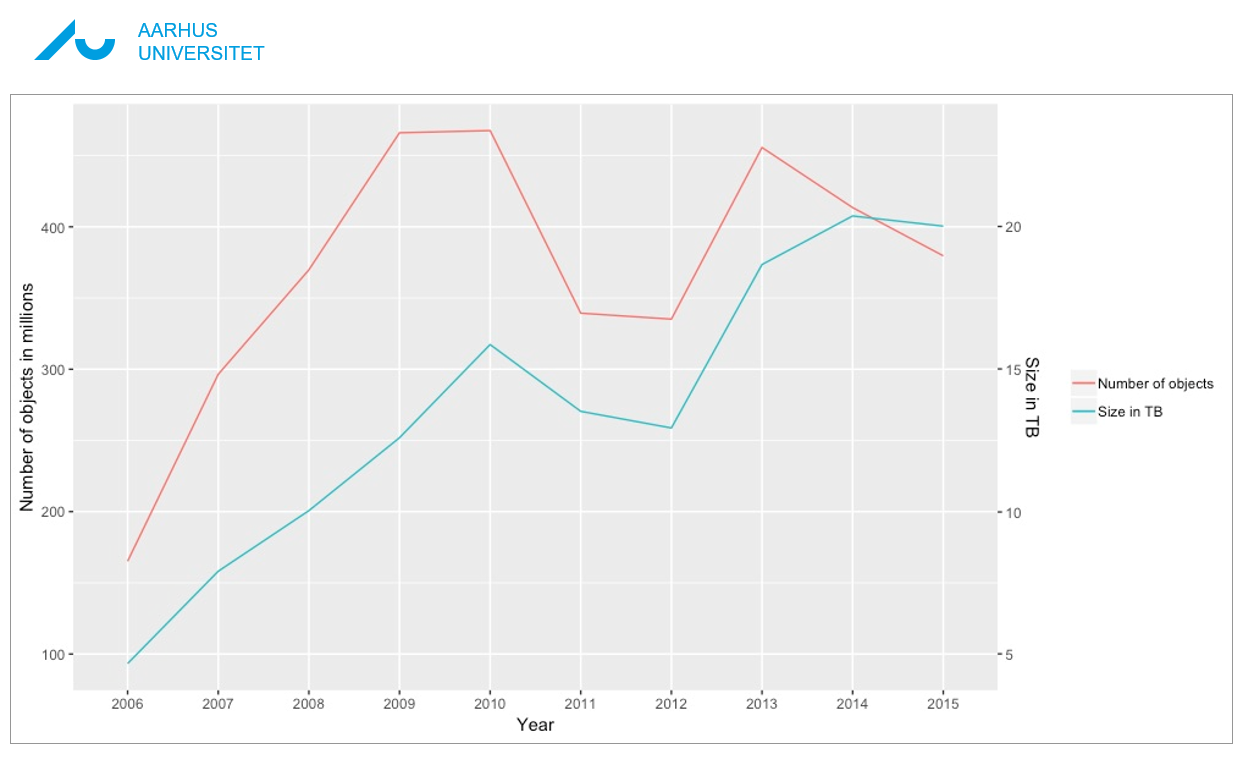
Det danske webs udvikling i perioden 2005 til 2015.
”Vi har prøvet os frem, og derfor har der været rigtig meget dokumentation i processen, hvor vi hele tiden har holdt styr på vores forespørgsler og søgninger. På den måde har vi løbende præciseret metoden og defineret regler for analyserne,” forklarer Niels Brügger.
Kulturarvsclusteret har i den forbindelse været en uundværlig partner, for optællingsarbejdet er yderst omfattende i disse datamængder.
”Samarbejdet mellem it-folk, arkivfolk og forskere har også været en nødvendighed for at nå frem til konkrete resultater. Det har naturligvis krævet, at vi skulle tale det samme ’sprog’, så vi kan kommunikere præcist med hinanden. Det tager tid, men det er en spændende og givende proces.”
Kort fortalt skal forskerne vide hvad, der kan lade sig gøre, og forskerne skal fortælle it-folkene præcis, hvad de leder efter.
Nu er samarbejdskulturen, computermodellerne og algoritmerne så på plads og det omfattende arbejde har placeret Danmark solidt på verdenskortet i forholdt til kortlægning af nationalt internetindhold.
”Vi er de første i verden, der har anvendt HPC til at foretage analyser af nationale dele af internettet, hvilket har betydet, at der er stor interesse fra udlandet vedrørende vores projekt,” fortæller Niels Brügger.
Alt arbejdet er detaljeret beskrevet og scripts ligger offentligt tilgængeligt, så udenlandske forskere kan bruge erfaringerne fra projektet til at analyse andre dele af internettet.
Resultaterne af Niels Brüggers forskning kan læses i de følgende publikationer:
- The Archived Web: Doing History in the Digtal Age.
- The SAGE Handbook of Web History.
- The Historical Web and Digital Humanities: The Case of National Web Domains.
Kort om projektet
Det overordnede formål med projektet er at analysere hele det danske webs historiske udvikling baseret på materialet i det danske webarkiv Netarkivet. De første ideer til projektet blev formuleret i 2014, men de lod sig først udfolde i egentlige analyser, da Kulturarvsclustret kom til. Projektet fortsætter i resten af 2019, og det er støttet af Aarhus Universitet, af Det Kgl. Bibliotek, og i 2016-17 ligeledes af Kulturministeriets Forskningsfond.




